
I'm proud to announce the 1.0 release of Cloudless, an open source computer vision pipeline for orbital satellite data, powered by data from Planet Labs and using deep learning under the covers. This blog post contains details and a technical report on the project.
Note: this article uses Stretchtext, which are dashed and bordered boxes like this one and which can optionally be clicked and opened inline to learn more details about a subject.
This is some example Stretchtext; computer screens aren't paper -- we can move beyond simply mimicing paper. Stretchtext makes it possible to "crack open" and learn more inline about a subject, going deeper
Stretchtext is based on ideas from Ted Nelson; this page uses stretchtext.js, an open source implementation of Stretchtext I created a few years ago for the browser.
The Cloudless project was born during Dropbox's week-long Hack Week in August 2015 with contributions from Johann Hauswald, Max Nova, and myself; I've continued working on the project post-Hack Week to bring it to a 1.0 release, generally during the weekly colearning groups I run.
Hack Week is a Dropbox-tradition where engineers and invited guests get to work on any project, no matter how blue sky.
Colearning are weekly study groups I created to help give structure and community to the self-education I've been doing in deep learning and computer vision. They are a chance for people to make progress on an online course or project that's important to them - think of it like a writers group or a study group for adults. They are similar to coworking. I worked on Cloudless for a few hours each week in my colearning group for a several months.
I created coworking many years ago because I wanted structure and community around work; colearning is the same thing, but around having physical structure and community within the freedom of doing online learning.
Planet Labs is a startup company that has launched fleets of nanosats, each about the size of a shoebox, to image much of the earth daily. They've launched about eighty of their nanosats, called Doves, into Low Earth Orbit, via both the International Space Station (ISS) and as secondary-payloads. Doves are built from commercially available hardware and can be placed into orbit quickly, resulting in much lower prices per satellite and allowing much more rapid iteration in what is known as “agile aerospace.” Planet Labs approach is in contrast to traditional geospatial imaging satellites, which cost billions of dollars, take five to ten years to develop, and are launched into geosynchronous orbit.

Once Planet Labs full fleet is deployed 90% of the earth's surface will be imaged once daily. This will result in a flood of visual data that is greater than any person can efficiently process. Can we have computers do the detection and localization of items in the orbital satellite data instead?
Interesting applications of automated visual satellite detection are counting the numbers of cars in Walmart parking lots as a correlate of daily consumer demand or detecting deforestation from illegal logging operations. The Planet Labs resolution is currently three through five meters, which is not great enough for counting cars, however, and publicly available forestry deforestation data sets are not suitable yet.
For this reason we focused on automated cloud detection, hence the name Cloudless (which is also a pun for the fact that the project originated during Dropbox’s Hack Week, a cloud-based company — who says deep learning can’t be funny).
Detecting clouds in orbital satellite imagery to ignore or eliminate them is an important pre-processing step to doing interesting work with nanosat imagery as we want to detect changes over time, such as cars appearing, forests disappearing, etc. Being able to first detect and eliminate clouds (which change often and could lead to false positives), is therefore important.
Note that even though the Cloudless pipeline is currently focused on cloud detection and localization, the entire pipeline focuses on what would be needed for any visual orbital detection and localization task and with tweaking can be applied to other problems.
Cloud detection and elimination are by no means solved problems. However, there are currently two broad non-deep learning approaches for cloud detection and elimination that help with the problem.
The first involves detailed, hand-rolled feature extraction pipelines that attempt to extract relevant pixel-level details from infrared, thermal, multispectral bands, etc. and then use various thresholds that are sometimes location, day, and season-specific. They are complicated and not necessarily universal. In addition, the Planet Labs satellites only currently work in the visual spectrum (except for a few satellites gained through a recent acquisition named RapidEye, which can detect in the near infrared), which means the multispectral and thermal bands some of these techniques depend on are not present. A good survey of these hand-engineered approaches is in [1].
The second approach involves taking a stack of satellite imagery of the same location over many days and “averaging” them together. This will by definition remove the clouds from the image, leaving consistent details such as cities, roads, surface details, etc. behind. Unfortunately, it also removes much of the “changes over time” information, stripping away what makes Planet Labs imagery so compelling. A good example of the stacking approach is in an open source library from Planet Labs themselves named plcompositor [2].
As a side note not pursued in this project, an interesting approach might be to use such stacked images to get a "constant" image that represents unchanging elements of a location. Then, when a new image from this location comes in, compare it to the constant image to get a difference mask to see what has changed within this location. This difference mask could then be passed downstream to other deep or non-deep learning pipelines to infer what should be focused on in the image for object detection and localization; perhaps one way to think of it is as helping a neural network attention model to know what to spend its time focusing on.
Convolutional neural nets (CNNs) have shown surprisingly strong results in image classification tasks in recent years and seem to be a natural fit for this problem. Once trained, a CNN can be used to do object localization to draw bounding boxes around candidate detected items. However, supervised training of CNNs depends on large amounts of training data, which does not readily exist for orbital satellite data, requiring us to bootstrap it ourselves. Cloudless therefore consists of three pieces:
The annotation tool is fairly straightforward; it draws imagery from the Planet Labs API, normalizes and pre-processes it, and then presents it to a user through a web browser to draw bounding boxes over candidate objects:

The training portion takes the annotated images, chops them into pieces representing images that either have clouds or not, splits them into 80% training and 20% validation sets, and trains a binary classifier on Caffe. The model itself is a fine-tuned version of AlexNet. The open source project includes scripts to train these on GPU-instances on Amazon EC2 to explore different hyperparameter settings in parallel quickly and to download and query the trained results to understand how well training went on the validation data; see two examples graphs generated from the training pipeline
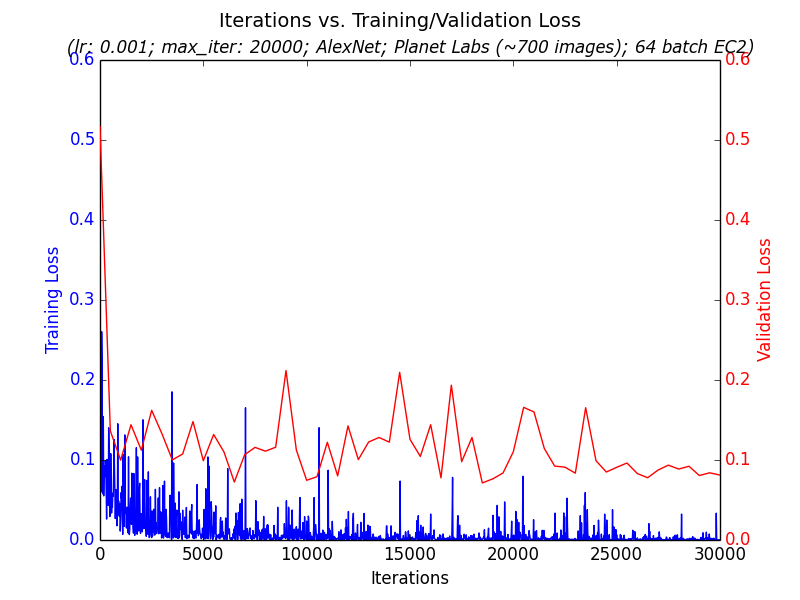
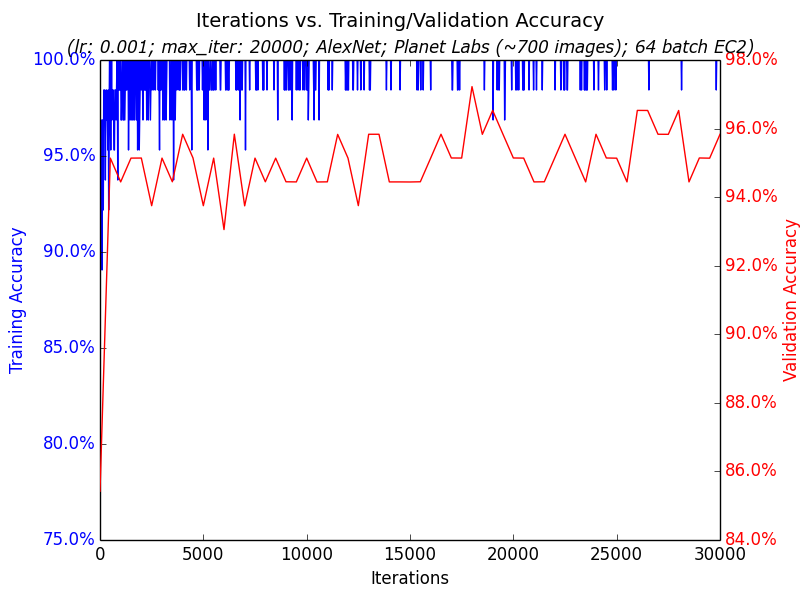
As a side note not pursued in this project, an interesting approach might be to use such stacked images to get a “constant” image that represents unchanging elements of a location. Then, when a new image from this location comes in, compare it to the constant image to get a difference mask to see what has changed within this location. This difference mask could then be passed downstream to other deep or non-deep learning pipelines to infer what should be focused on in the image for object detection and localization; perhaps one way to think of it is as helping a neural network attention model to know what to spend its time focusing on.
Finally, the trained classifier is fed into a Python-based implementation of Selective Search [3][4] in order to draw candidate bounding boxes around clouds. As part of the work on this project the Python Selective Search library was back ported from Python 3 to Python 2.7 to be compatible with Caffe and the rest of the Python-2.7 based Cloudless pipeline. Here are example before and after output showing detected clouds on the final trained model (detailed more below in the Trained Model section); detected clouds are overlaid with yellow boxes below:


The bounding box system also outputs a JSON file that gives detected cloud coordinates for later-use by possible downstream computer vision consumers.
It took quite a number of iterations to get a model with decent results. The major approaches are detailed in Table 1, with the final best approach bolded:

All iterations were based on a BVLC AlexNet Caffe Zoo trained model [6], with fine tuning done on Cloudless annotation data. Convolutional layers were frozen during fine tuning, with training done only on the final fully connected layer. The AlexNet ImageNet output softmax was reduced from one-thousand classes to two, indicating whether a cloud is present in a given image or not. All iterations had a standard 80/20 split between training and hold-out validation data. The number of training epochs for most runs converged fairly quickly, as you can see in the graph below. Finally, all iterations used location imagery restricted to the San Francisco Bay Area as we were restricted via the Planet Labs API to the state of California.
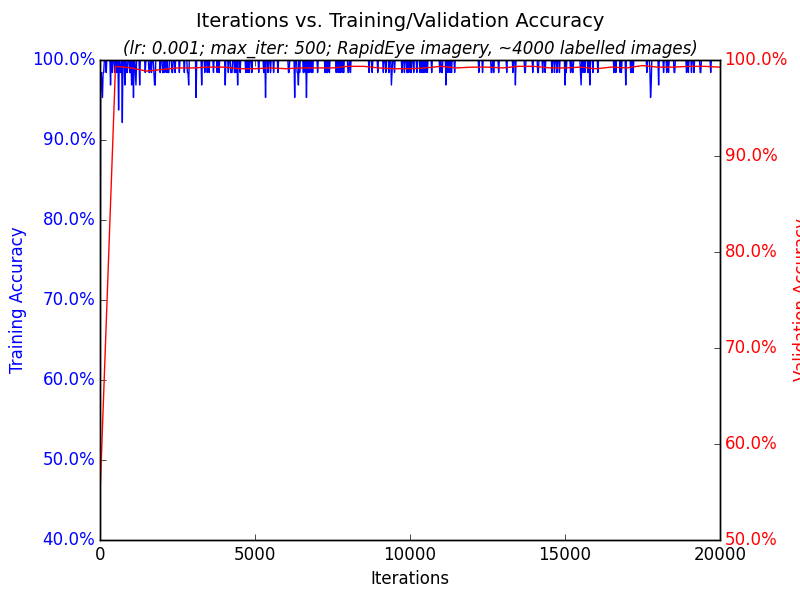
700 images from the Planet Labs API were hand-labelled via the annotation tool and trained; the final accuracy was fairly low, only 62.5%. This was discovered to not necessarily be from small amounts of data, but rather from fairly extensive “motion blur” affecting some satellite imagery. An example is shown below:

Despite this, the bounding boxes generated were still in the realm of plausibility, though with some false positives caused by the motion blur. An example from the earlier image:

Getting to a better accuracy involved three things:
1) About two months after Cloudless was started Planet Labs purchased a fleet of satellites named RapidEye. The data from these are clearer than the Planet Labs satellites currently are. An example image:

2) The same location but over 65 days were annotated and fed into the network, allowing the network to ‘learn’ what is constant in a location and what changes. Here's four days of the larger-format imagery that fed into the annotation tool as an example:




In affect the network was getting examples of what the San Francisco Bay Area looks like when it’s clear and when it’s cloudy, allowing it to generalize from this.
3) More images were hand-labelled with the annotation tool, totalling about 4000 images.
These three steps added up to a much larger final accuracy of 89.69% on the validation data, with much stronger precision and recall than the earlier run. While its difficult to say exactly how the hand-engineered non-deep learning cloud detection pipelines detailed in Related Work above and in [1] perform, as its fairly dependent on location and hand-chosen threshold, general performance accuracy is reported to be in the 80% to 90% range, making Cloudless generally competitive with them. Unlike those other solutions, however, Cloudless could be fed with multi-class annotated data and trained for a wide variety of tasks without a hand-rolled feature engineering pipeline focused just on clouds.
For the final best solution see the final confusion matrix and details on the raw data fed into neural network training pipeline
Experiments were done to attempt to get beyond the 89.69% accuracy via greater data augmentation. All iterations used Caffe's built-in clipping and mirroring transformations during training; experiments were done however with manually rotating all labelled images via data preparation 90 degrees in four directions to see if this aided training. Counterintuitively, though, performance was actually lower, as detailed in table 1 above.
Since Cloudless uses only visible spectrum imagery, it does not work with night-time images. In addition, Cloudless has not been trained or tested on regions with snow, which has been reported to cause issues with other cloud detection schemes.
In addition, the Selective Search bounding box scheme chosen is fairly computationally intensive. On my Macbook Pro laptop with a 2.5 GHz Intel Core i7 and an NVIDIA GPU, for example, processing a single image took about two minutes. This is not terrible for Planet Labs, as a given location would only be imaged once a day and this task can be parallelized fairly easily.
Unfortunately, generating the bounding boxes depends on a number of hyperparameters for Selective Search that are not always generic across input images and requires some hand tuning for a given location; it's not always “hands free” yet. Example hyperparameter values are given on the Github Cloudless page. This motivates some of the ideas in the “Future Work” section below.
A good future step is to eliminate Selective Search's computational slowness and hand-crafted hyperparameter tuning from the equation. One possibility is to turn the convolutional neural network currently in Cloudless into a deconvolution neural network [7], feeding in a raw image and having the output be a pixel mask where each value is the class of that pixel, whether its a cloud or some other desired classification and localization. This might allow the network itself to learn what hyperparameter “thresholds” are appropriate for different input images, eliminating the kind of hand tuning the Selective Search bounding boxes currently require, as well as providing pixel-level classification.
To increase accuracy in general, it‘s clear from non-deep learning cloud detection techniques that non-visible spectral bands can be important for inferring the presence of clouds or other items. When a user annotates a satellite image in the annotation tool in the visual spectrum, other side-channel non-visual bands can be saved and also fed into the network, such as infrared, thermal, etc. As Planet Labs integrates greater spectral bands into their satellites this will become more of an option.
In addition, we should be able to feed in the latitude, longitude, altitude, day and time of the year, and the position of the sun of each pixel as input into the network. This is clearly information that a human themselves would use to identify what something is. For example, if you were told that an image came from the North Pole, you would probably classify a white patch as snow if you were unsure, while if you were told it came from the equator in a tropical forest you‘d assign a very high probability to a blury white patch as being a cloud. If you weren’t sure what a white patch was while looking at an orbital image of NYC, you'd probably have different answers if you knew it was winter or summer. It seems only natural to give these same features to a neural network to help it decide when its dealing with “boundary” cases where its not quite sure; having this information would allow it to essentially take a Bayesian approach to figuring out what it is looking at to make an informed guess.
Finally, the annotation tool itself can be extended to run on Mechanical Turk to bootstrap even more data, which would probably be necessary if the deconvolution approach earlier is taken as it has more free parameters to train. If this is done, the annotation tool will have to be extended with a training step to gauge how well labellers do as well as a validation step to run labelled data by other groups of users to gauge their quality, as in [8]. Once done, and once Planet Labs has satellite data with a greater resolution, this can be used to bootstrap multi-class data sets with examples of cars, roads, power lines, ocean tankers, buildings, different biomes, etc.
In this blog post I've introduced Cloudless, a three-part open source orbital satellite pipeline that provides annotation tools, a deep learning component, and a bounding box system. It is currently focused on cloud detection and localization, but could be extended for other non-cloud tasks in the future. The final trained model has an accuracy of 89.69% on cloud detection, generally competitive with hand-tuned non-deep learning cloud detection pipelines.
One strong aspect of deep learning is that future proposed enhancements, such as those detailed in “Future Work” above, should help with end-to-end learning of most computer vision oriented orbital satellite data tasks, not just cloud detection tasks. Rather than just increase cloud detection such as with other non-deep learning oriented approaches that use manual feature engineering, investments in deep learning can help improve a wide range of computer vision tasks beyond just the problem at hand.
The GitHub page for Cloudless can be found here.
Special thanks to Johann Hauswald and Max Nova for their help on Cloudless during Hack Week, to Planet Labs for graciously giving us access to their data and API, and for Dropbox for making space for Hack Week and Cloudless.
[2] Frank Warmerdam, Pixel Lapse Compositor (plcompositor)
[3] J. R. R. Uijlings et al., Selective Search for Object Recognition, IJCV, 2013
[4] Koen van de Sande et al., Segmentation As Selective Search for Object Recognition, ICCV, 2011
[5] Brad Neuberg, fork of Selective Search
[6] Caffe Model Zoo
[7] Hyeonwoo Noh et al., Learning Deconvolution Network for Semantic Segmentation
[8] Hao Su et al., Crowdsourcing Annotations for Visual Object Detection
Subscribe to my RSS feed and follow me on Twitter to stay up to date on new posts.
Please note that this is my personal blog — the views expressed on these pages are mine alone and not those of my employer.