Large Scale Distributed Systems for Training Neural Networks Tutorial
Jeff Dean and Oriol Vinyals
Google
Started in perceptual domain in 2011 and moving towards more tasks, in particular language translation
Taking research systems into production systems
Can be used for more than just neural nets
Systems that are easy to express but also easy to scale
Universal machine learning: same basic learning algorithms work across many domains
Distbelief good for production use but not for research use - not flexible for things like reinforcement learning or some funky LSTM architecture, for example
Motivation: train large models with lots of data fast
General trend is towards more complex models: embedding of various kinds, attention, memory, generative models
Lots of frames from YouTube with autoencoder to recreate frames - 1000 machines on 10 million images, system automatically learned very high level features
Speech: feed forward acoustic models, taking acoustic data and matching it to speech
Speech models are getting more complicated, using deep LSTM layers and convolutional layers
Trend: LSTMs end to end!
Makes system simpler to express and perform better as there aren't arbitrary layers, end to end model can discover correct layering
Inception-v3 from this month - new drop in error rate

Inception had many fewer parameters because it removed the fully connected layer
Trend: in distributed learning you are shipping parameters around, so you want to have less model parameters
Batch normalization gave a nice drop in error rates
Models with small number of parameters fit easily in a mobile app (8-bit fixed point)

Just released new state of the art model for use by others
Runs on mobile
What do you want in a research system? Ease of expression, scalability, portability, reproducibility, production readiness
Updates for distributed tensorflow implementation coming soon
Tensorflow architecture: core on c++
Graph execution engine, supports wide variety of devices and that core is extensible
Runs on Linux and android, internal version running on iOS not yet released
Different front ends for specifying graphs and computations
Python and c++ today
Going to ship distributed system that used kubernetes and grpc for distributed bits
Whenever an edge crosses a device boundary, graph gets rewritten to have send and receive nodes to receive values when ready
Send and receive node abstractions work under different scenarios: multiple gpus, cross machine rpc, gpus on different machines, etc.
All complexity of transferring data captured by send and receive nodes
Core system has standard operations (add, jpg decoding, etc) and kernels (device specific implementations of operations for speed ups)
Easy to define new operations and kernels
Session interface: client describes graph using series of extend calls that add nodes to graph, then run to execute sub graph, optionally feeding in tensor inputs and getting tensor outputs, useful for debugging
Typically, setup a graph with one or a few extend calls and then run it thousands or millions of times. Generally system can work under the covers at extend time to be more efficient at run time.
Single process configuration
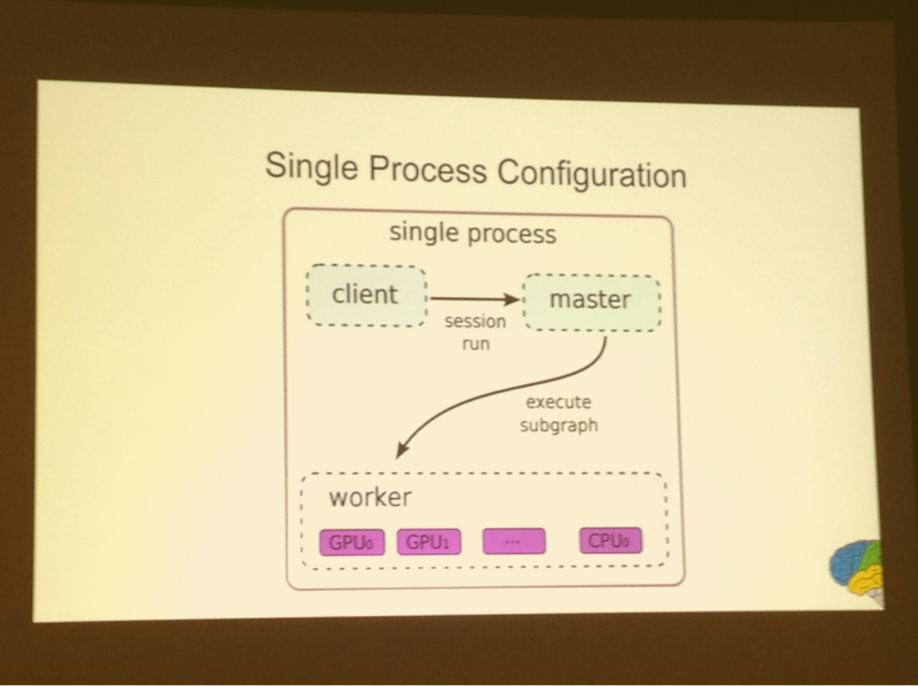
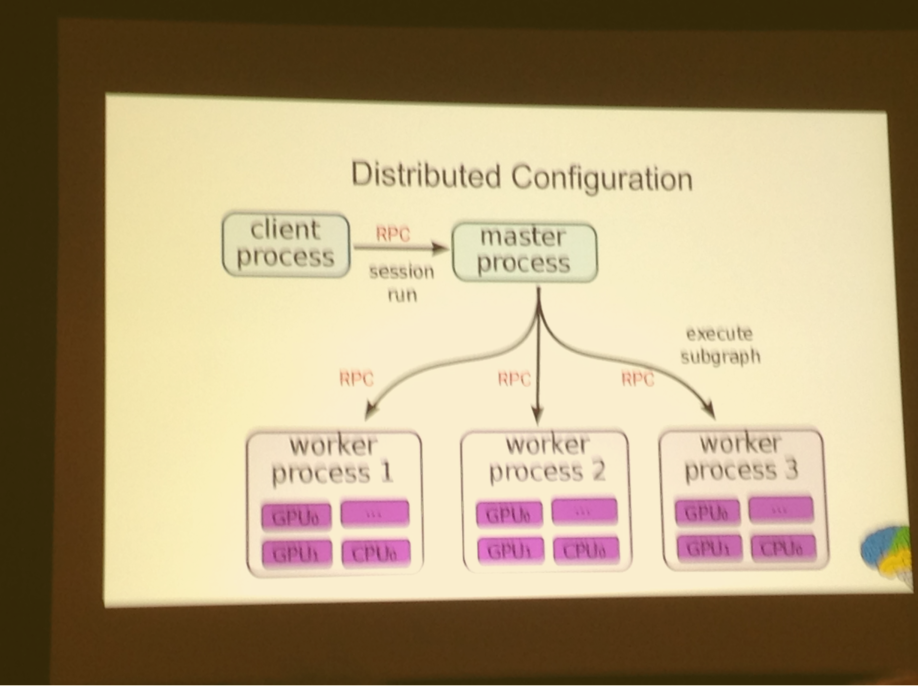
Being able to execute arbitrary input and output tensors to run makes debugging much easier
Can be used to have multiple graphs together for different uses
Example: power method for eigenvectors
Tensor board - tool for showing graphs
Example: symbolic differentiation
SummaryWriter - used to write out graph for debugging
Placeholder - a variable that will change on each input of the graph (i.e. It's the data you want to input)

Initial results on single device not great
New code they are working on:

Future step is update to latest CuDNN libraries, won't make it into 0.2 release
Single device important but most focused on distributed performance
Distributed bits give a greater speed up than single device
If you can turn around your research in minutes or hours than very powerful
How do you do this at scale?
Best way to decrease training time: decrease the step time
Many models of inherent parallelism, problem is distributing work so communication doesn't kill you - local connectivity (cnns), towers with little or no connectivity, specialized parts of model active only for some examples
Fully connected layers very expensive in terms of this
On a single core: SIMD to get instruction parallelism
Across cores: thread parallelism
Across devices: for gpus, often limited by PCIe bandwidth
Across machines: limited by network bandwidth and latency
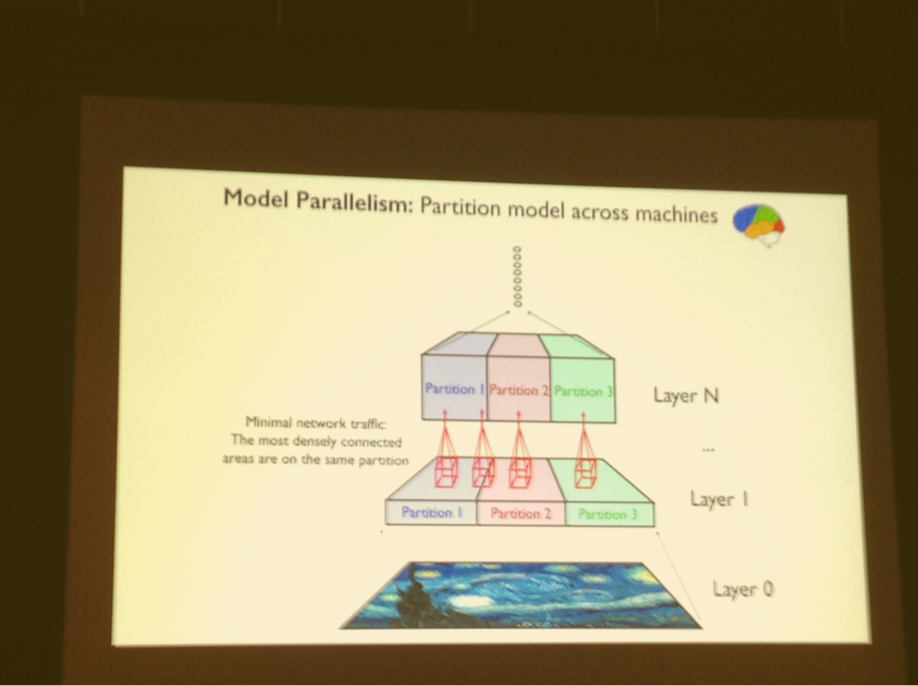
Model parallelism can reduce step time, most effective way to speed up training time
Data parallelism - can work in conjunction
Use multiple model replicas to process different examples at the same time, 10 through 40x speed up

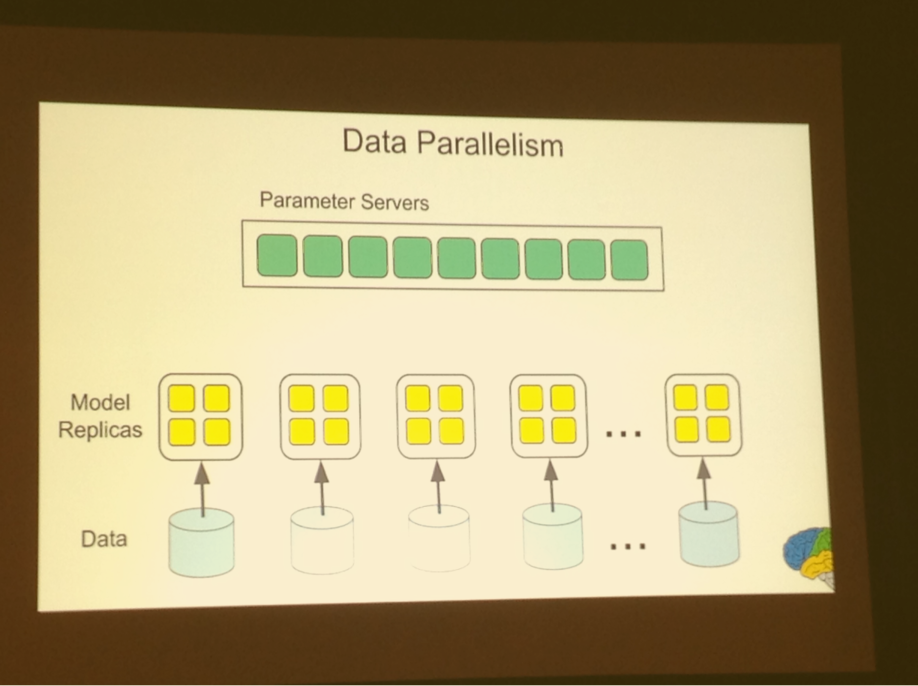

Ten to a thousand replicas work fine in asynchronous regime
Want models to not have too many parameters because of network time
Mini batches of size B reuse parameters B times
Convolutional models tend to reuse hundreds or thousands of times per example
Recurrent models tend to reuse tens to hundreds of times T time steps due to unrolling during training
Want model computation time to be large relative to time to send and receive parameters over network
Data parallelism is really imports for many of googled problems (very large datasets, large models): rank brain uses 500 replicas, Imagenet inception training uses 50 gpus, 40x speed up
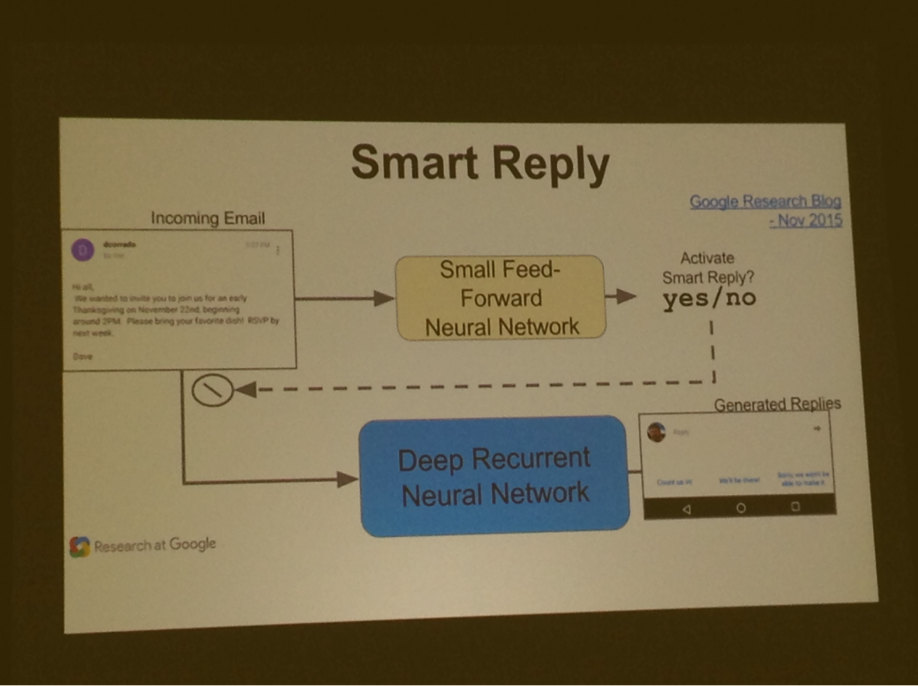
Smart reply uses 16 replicas, each with multiple gpus

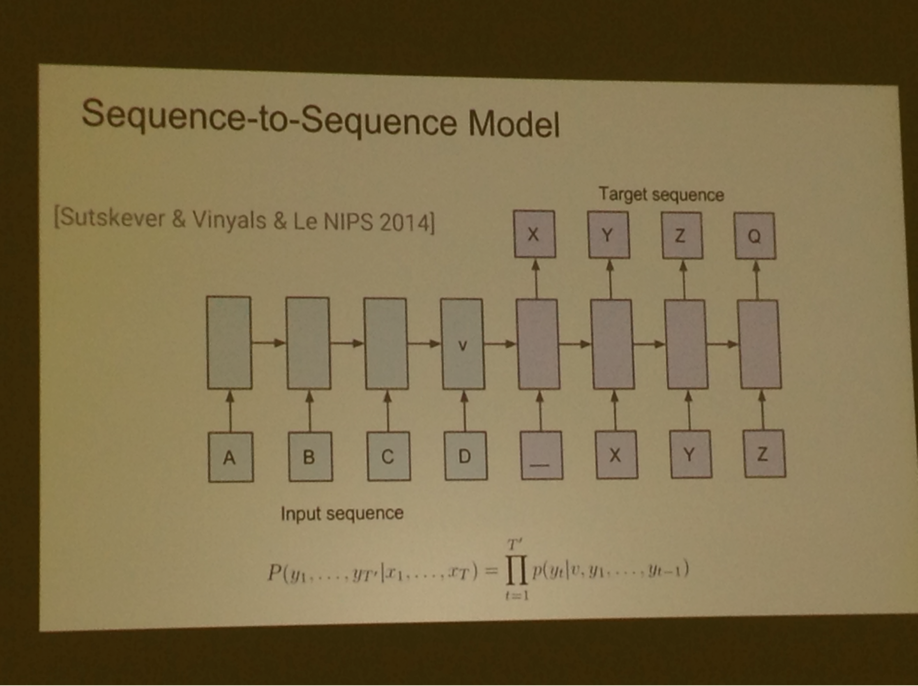
Trend: lots of LSTMs and creativity in neural network architectural approaches
Keeping things in memory for a long time was crucial

Would be very hard to deal with these without being able to translate equations into graph and symbolic differentiation
Trend: lots of people doing sequence to sequence paradigm problems
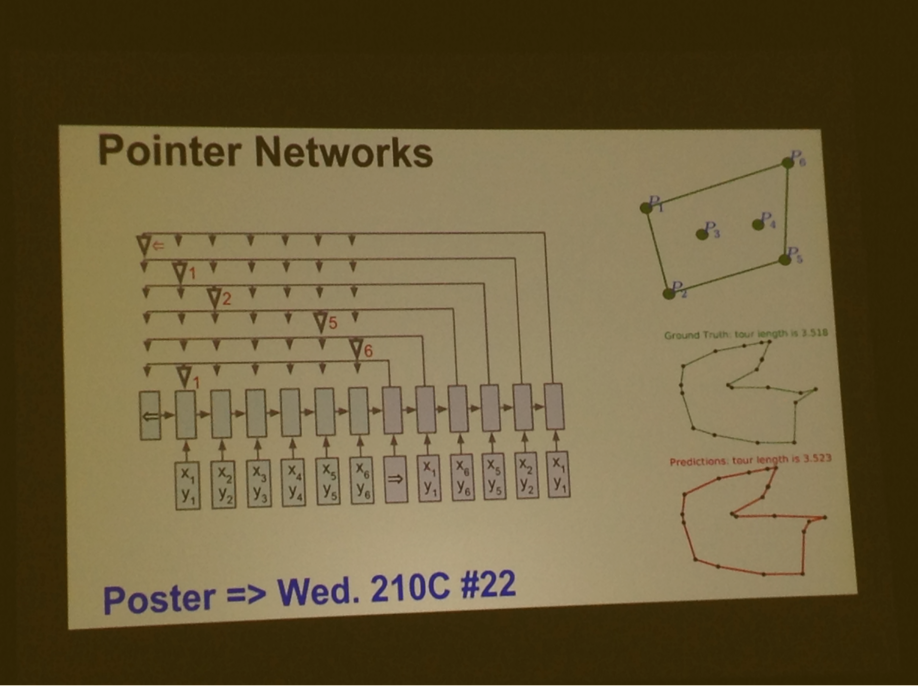


Deep LSTMs are very important

To go distributed:

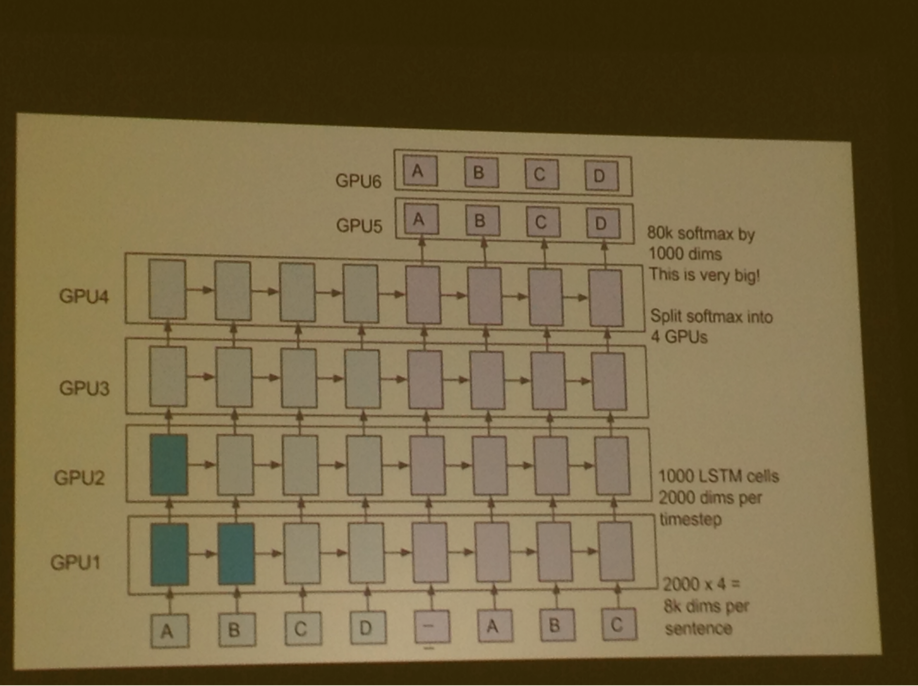
Tensorflow queues: put data in a queue, when it's full launch forward backward for however depth the queue has

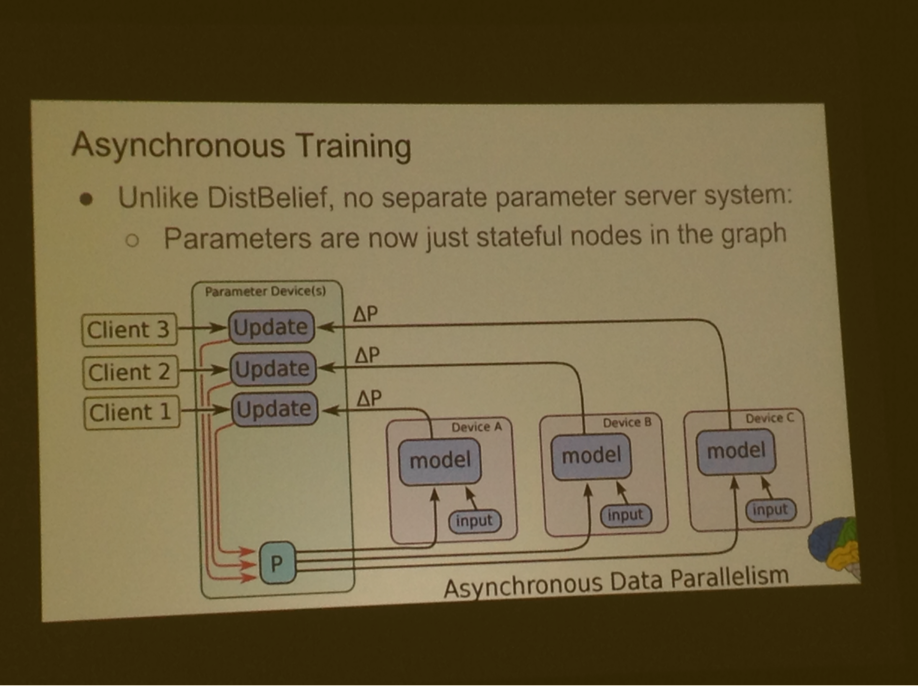
To make it asynchronous data parallelism:

Network optimizations: neural nets are very tolerant of reduced precision, drop precision to 16 bits across network, send and receive nodes can do this transparently, Google simply chops off 16 bits of mantissa
Quantization for inference: need even less precision for inference, 8 bit fixed point works well, figure out range of weights then scale to 0 to 255, with quantization can run at 6 fps on smart phone
Multi GPU in single machine in open source release
Distributed implementation coming soon issue 23 on github repo