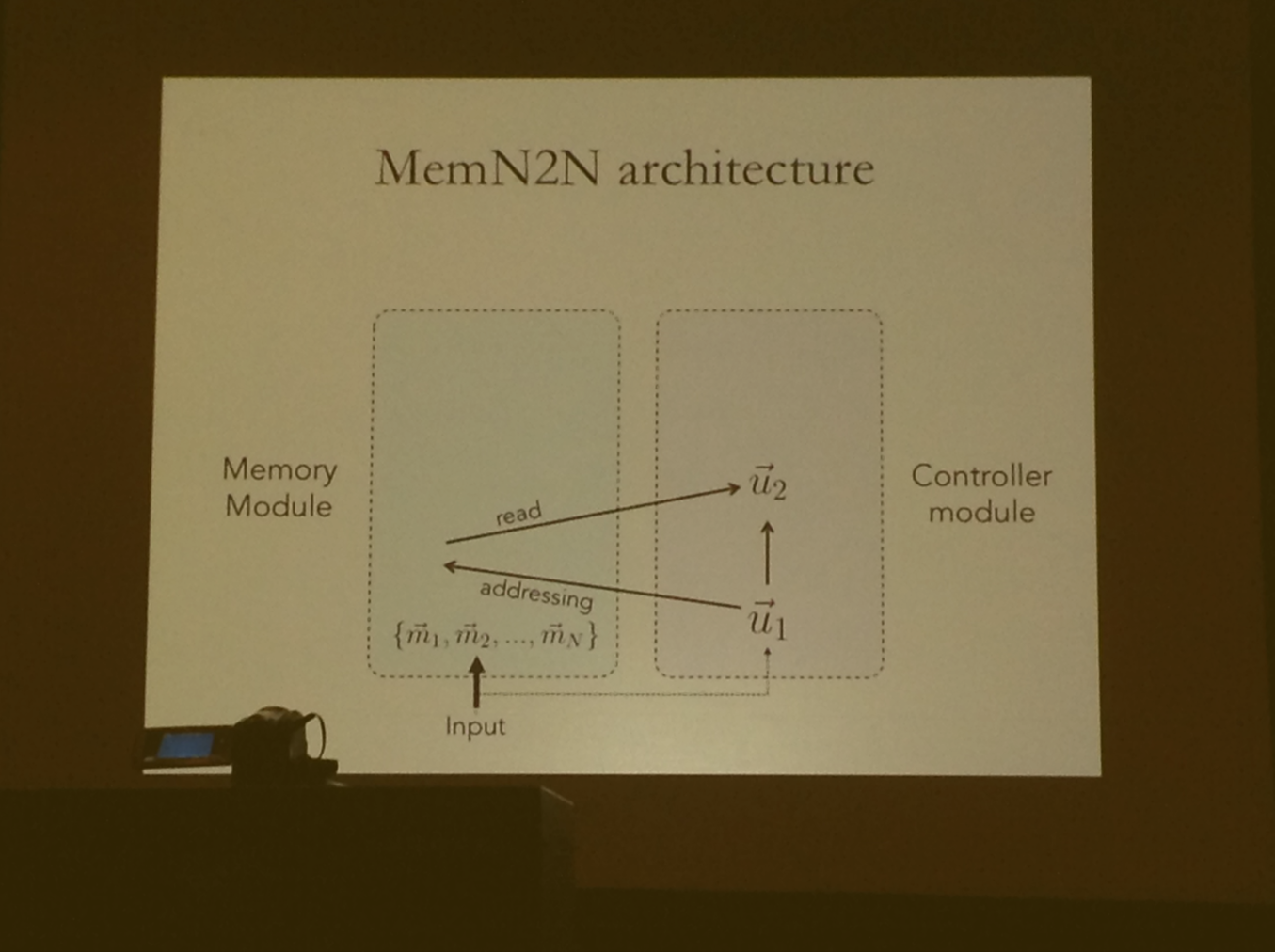
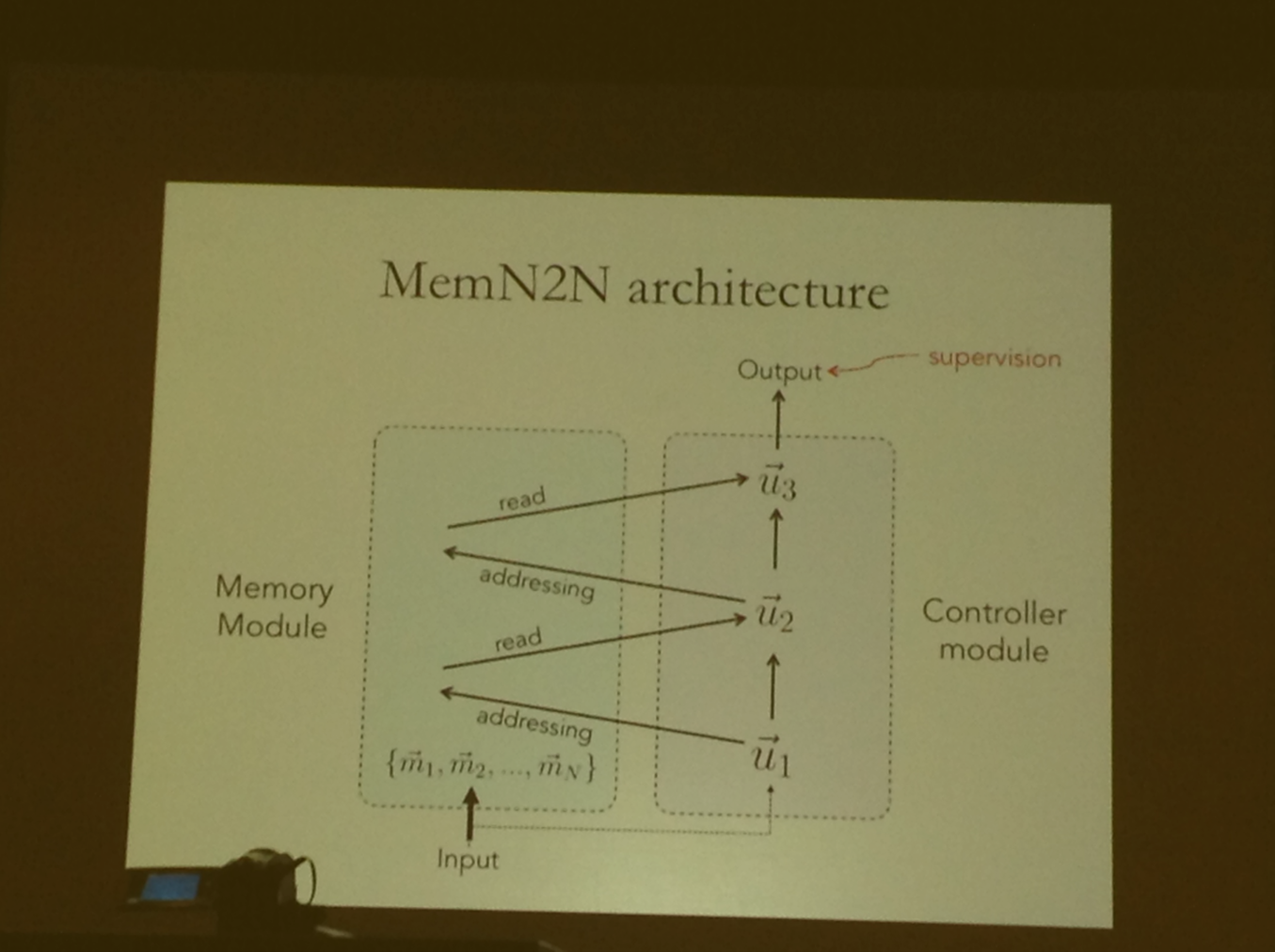
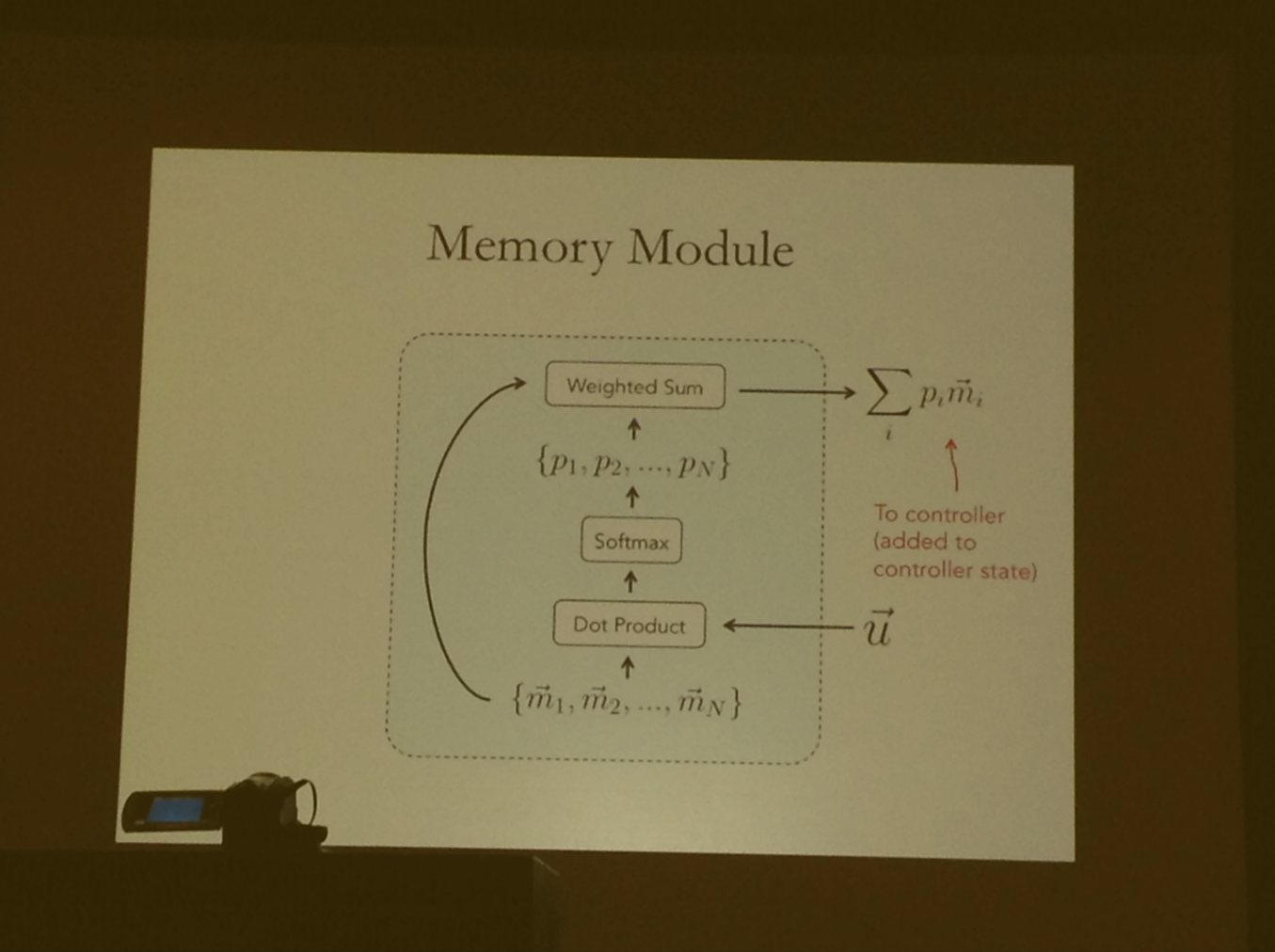
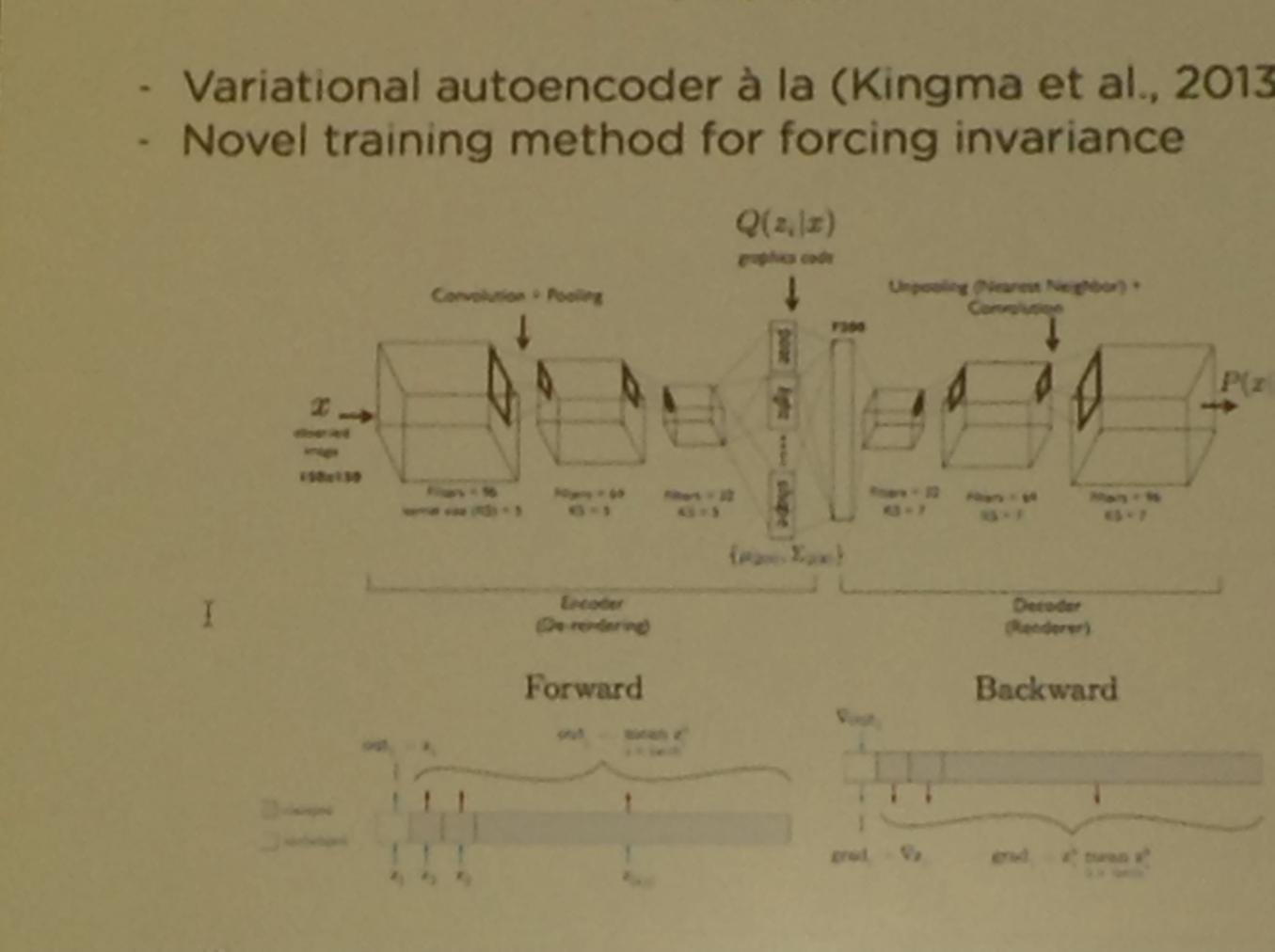
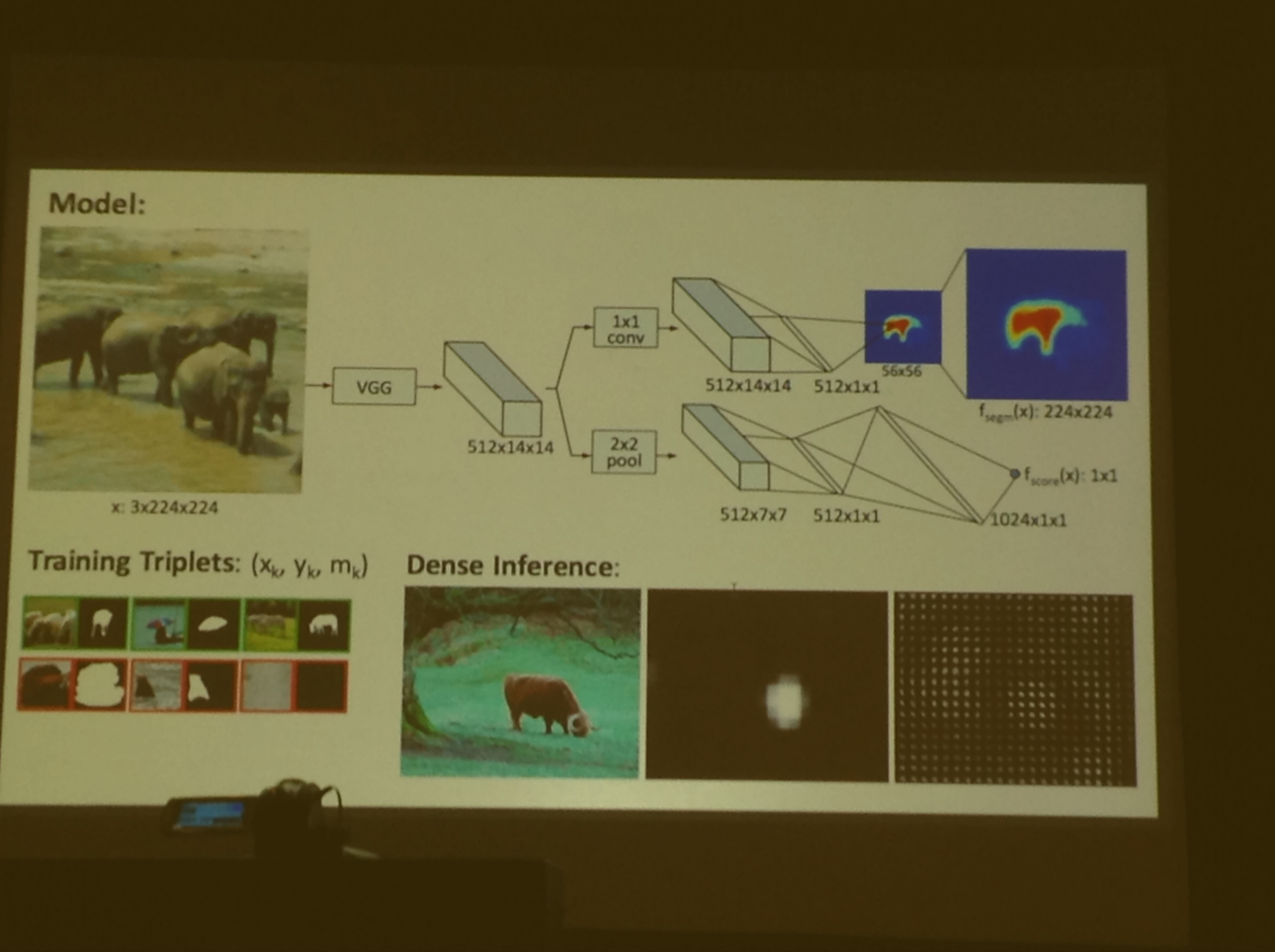
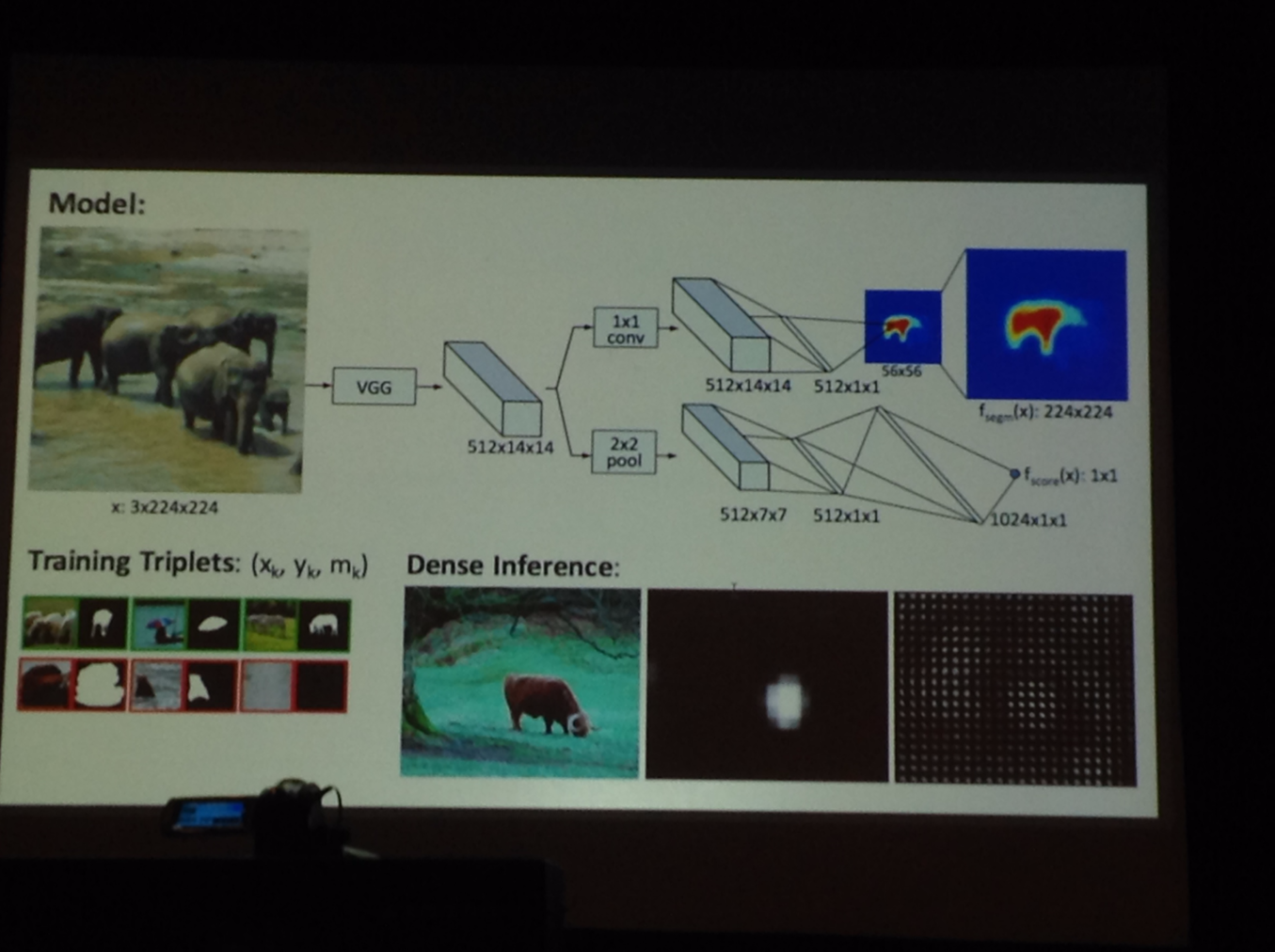
Deep Visual Analogy-Making



What they do differently is have a CNN trained end to end to learn analogical features
Seems like a hard problem
Create a function for each input image, and subtract them
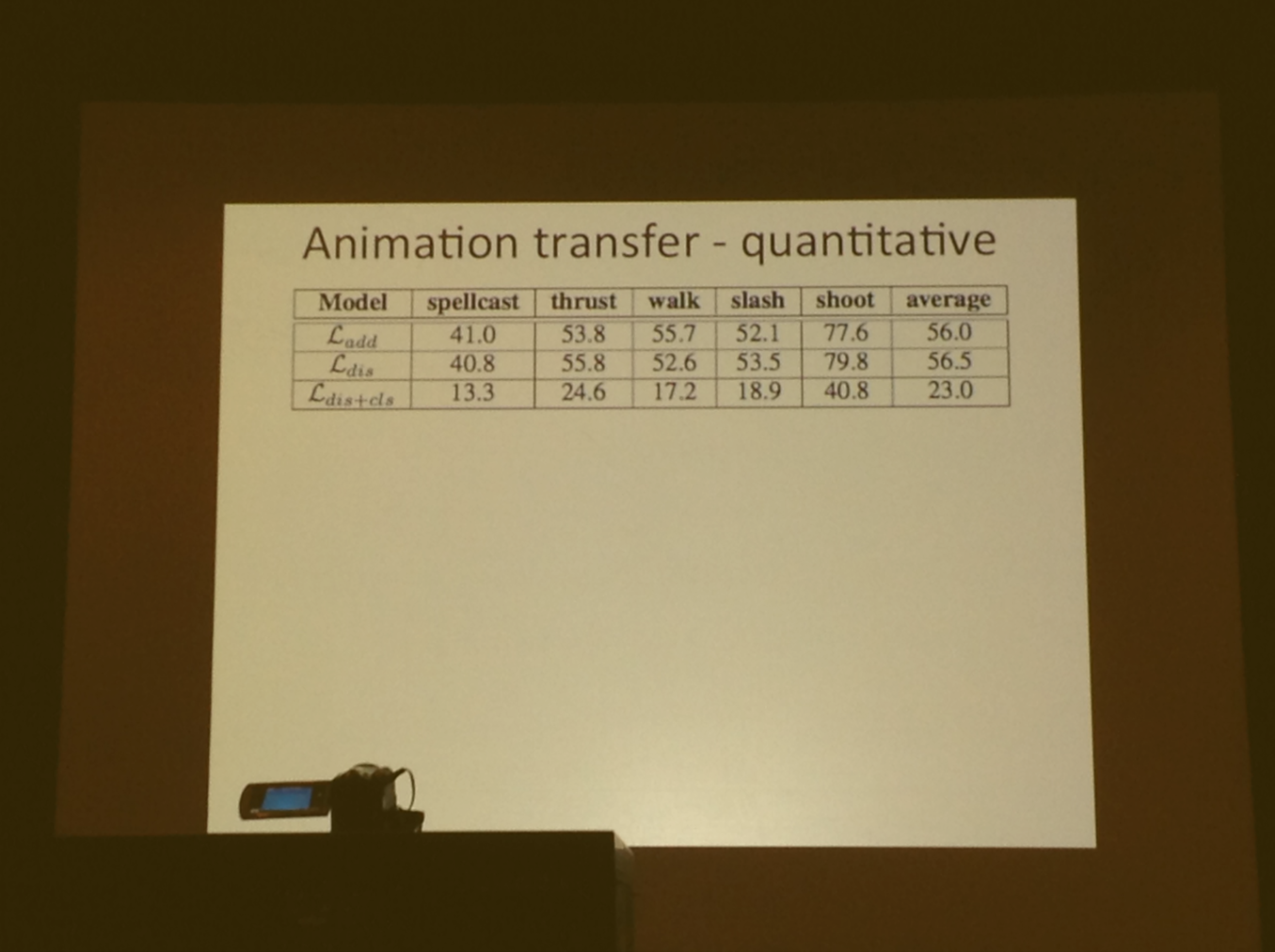
Additive encoders vs. multiplicative encoder vs deep encoding
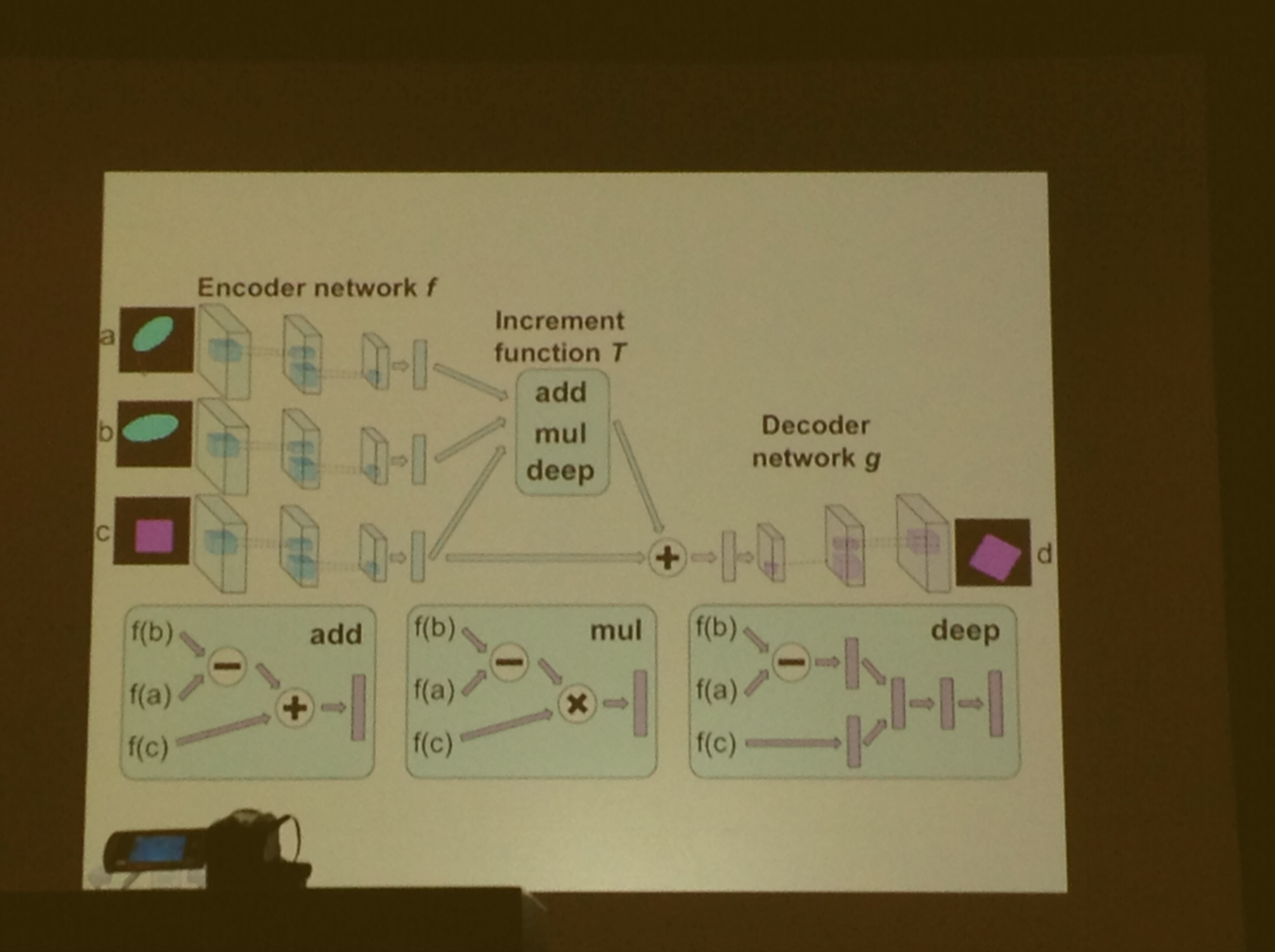



Deep model does the best vs add or multiplicative
one network that can do multiple transformations
Pretty cool results showing cartoon character being animated from transformation vector, even at different angles
Form training tuples of animations where the training samples are moving towards and backwards in time
Extrapolating animations by analogy
Then, apply these to query animation to unseen character
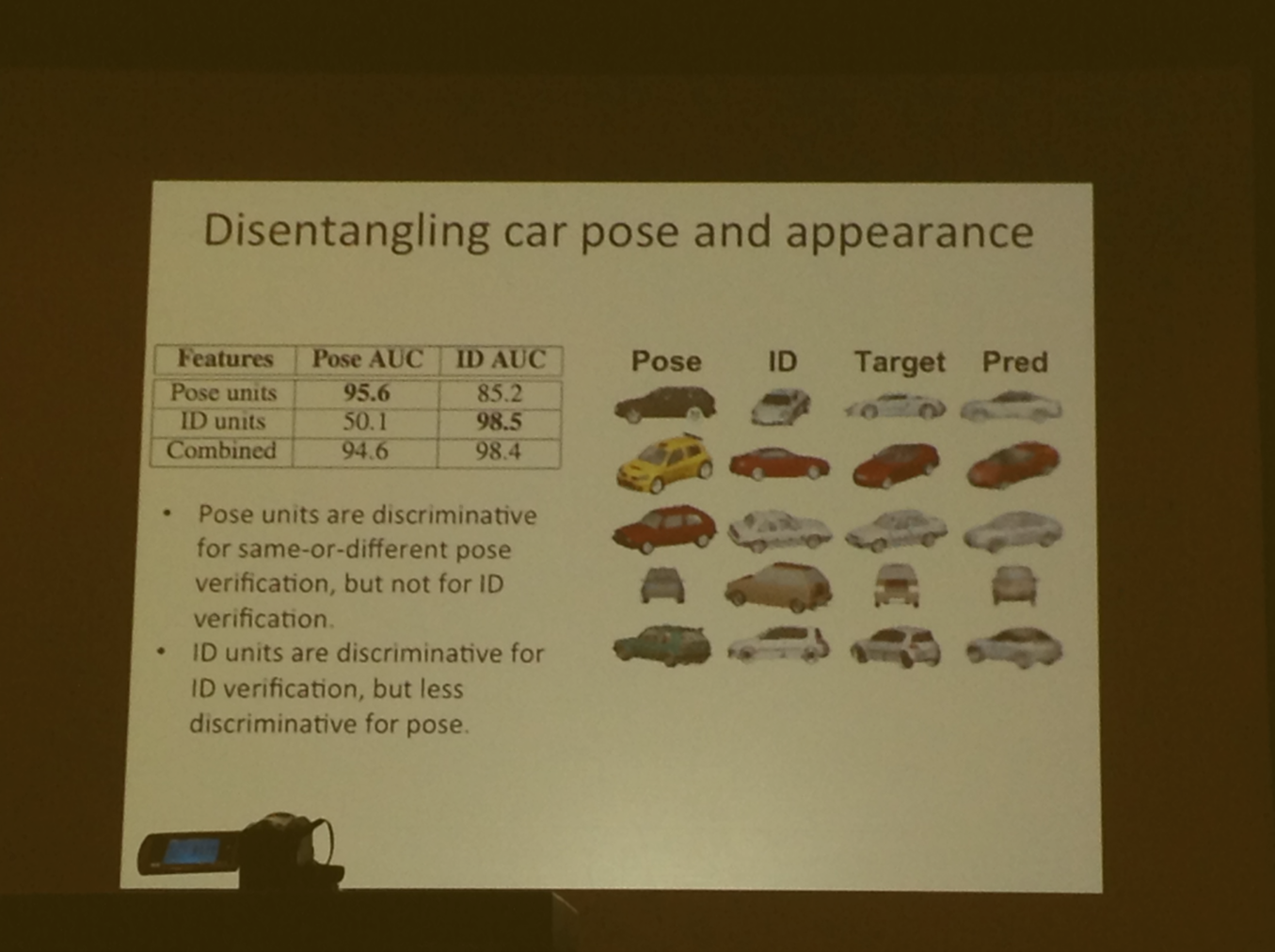
Disentangling car pose and appearance