
Last week I explained a bit about Inkling's process for converting back list books into next generation eBooks built with HTML5. I explained how the history of Inkling and Inkling Habitat is continually hitting bottlenecks in each of these steps, and throwing different ideas at bottlenecks to whittle them down.
Today I want to talk about some work we explored about two years ago around radically smart templates for books, focused on solving the content specification bottleneck.
As I mentioned last week, content specifications are basically examples and details on how to convert the different parts of a traditional book into its digital equivalent. I can't show any actual examples of them here as they are private to individual publishers, but I can show an example mockup of what one might look like.
Here is an example page from a traditional history textbook:
Almost all books have the same repeating patterns throughout them. For example, in the example page above, you see the subtitle "The Eastern Front and the Mediterranean" in red and fairly large; this history book probably has the same style and setup for all subtitles. You also see other elements that probably repeat throughout the book, such as the "History Makers" sidebar on the upper-left and the "Background" side footnote. If you were to turn to most of the chapters in this history book, you would probably see the same elements repeated and used; for example, this same history book probably has other Background footnotes (in fact the example above has two on the same page).
You can think of [a pattern library] like a higher-level version of movable type; instead of blocks of lead with individual letters, you have larger chunks you can use to build up your material.
All of the repeating elements in a book/eBook can be thought of as a pattern library. A pattern library consists of the lego blocks that you can put together to quickly produce a given book. You can think of it like a higher-level version of movable type; instead of blocks of lead with individual letters, you have larger chunks you can use to build up your material.
It's one of the jobs of a Content Architect to decide what the appropriate elements should be in a title's pattern library. In the example above, elements of that pattern library would probably include a standard pattern for History Makers; a standard pattern for sub-titles like "The Eastern Front and the Mediterranean"; a standard pattern for Background side notes; etc.
It turns out that most illustrated non-fiction eBooks have roughly the same semantic structure (i.e. they have headings, sub-headings, figures, block quotes, etc.). What differs is not their structural semantics, but rather how that is styled. It turns out in the digital world we have a great standard for dealing with semantic structure (HTML5), and a great standard for dealing with layout (CSS). This has allowed Inkling to have a boiled down pattern library that can be tweaked for individual series but which can be used to quickly provide the building blocks for titles. This is an important productivity booster, not unlike how the invention of interchangeable parts in the nineteenth century transformed industry.
A content specification, therefore, provides a mapping from a print textbook to the pieces from the pattern library that should be used when turning the physical book into a digital one.
Years ago Inkling would actually use a PDF showing images from the physical book, overlaid with notes detailing how the pieces of the physical book should be converted into their digital forms. This was the content specification, and the notes would be referencing things in that title's pattern library. The pattern library itself during that time was literally another document, with numbers next to each pattern entry name to uniquely identify it, such as "1.1 Figure", "2.1 Block Quote", "2.1.1 Half Width Block Quote", or "5.0 History Makers". Each of these patterns inside the document would have an associated chunk of HTML that should be inserted into the page if you wanted to use that pattern, so there might be a chunk of HTML to use for a "2.1 Block Quote" or a "5.0 History Makers", for example, that you would then fill in with the exact content you were actually writing or converting.
Here's an example of what one of these might have looked like then, as a fake PDF (mocked up, as the actual specifications are proprietary to publishers):

Basically, a content specification would have to be provided for each common element the first time it is encountered in the physical book. In the example above, you see little text labels pointing to each common element, referencing the pattern name that should be used whenever you encounter something else in the book that matches this.
These content specifications would be given to vendors to core convert an entire title to its digital equivalent. The vendor would literally have to sit with the PDF of the specification open in one window; when they saw something in the title that looked like it matched a given pattern, they would open the pattern library document and select the bit of HTML behind that pattern, then fill it in with the actual content from the book.
In fact, anything that depends on PDF is generally clumsy and inefficient. I hate to be tough on PDF but its true; PDF inherits the problems of physical paper, without the true benefits of digital publishing.
This system was clumsy and inefficient. In fact, anything that depends on PDF is generally clumsy and inefficient. I hate to be tough on PDF but its true; PDF inherits the problems of physical paper, without the true benefits of digital publishing.
We wanted to transform this process.
First, it turns out that Content Architects are not HTML experts, so we wanted to make it possible for a Content Architect to work with a palette of available patterns in a pattern library and drag these out while creating specification cards without having to know HTML. Then, the Content Architect could configure and specialize the pattern they had dragged out, again without having to know HTML.
Second, now that these specification cards would be HTML files instead of PDFs, they would get to integrate with all of the other features of Habitat, including seamless collaboration; actionable notes held in an issues database; a version control system; and so on. It turns out that specification cards aren't produced then thrown over a fence where core conversion happens; instead, its a dialogue, such that the spec card is refined based on findings as a book is converted. Having the spec card be HTML makes it possible to collaborate on the spec card itself and content produced from that spec card as conversion happens.
Finally, and this was the most ambitious element, we wanted to take the spec card that was produced, and once the entire book had been core converted into HTML, use that spec card to automatically gauge how closely the book had been converted according to the spec.
This was really important because it turns out that proofing is one of the biggest bottlenecks. However, proofing is a red herring, because it means that something earlier in the conversion stage happened that was incorrect. Having to manually scan through an entire book for higher level, architectural problems is very expensive and tedious.
What if you can take a specification card and magically use that as a machine readable description of how the rest of the book should be produced?
We gave ourselves an ambitious goal: what if you can take a specification card and magically use that as a machine readable description of how the rest of the book should be produced? Then, after the entire book has been core converted to an eBook, use that machine readable description to pop out a final score card that provides the quality of the book and tells you exactly where problems are. Powerful stuff.
Why would you want such a thing? The Kindle figured out how to scale and deal with simple prose content, but what about the world of complicated, illustrated, non-fiction, such as textbooks, cook books, and travel books? This content is much more complicated, and sometimes huge. As I mentioned last week, the Concise Textbook of Clinical Psychiatry on Inkling has fifty-three chapters alone! How do you scale that into a digital work?

I'm going to show you how this system worked for the end-user, then describe how it worked under the hood. However, before starting, I'll let the cat out of the bag: we've since moved past this particular piece of Habitat, but there's a lot of interesting work in here and lessons learned. The screenshots and architecture I describe below are from a few years ago.
I'm going to break down the UX step by step; the entire UI was accessed through a normal web browser. First, here is a screenshot of the Pattern Drawer:
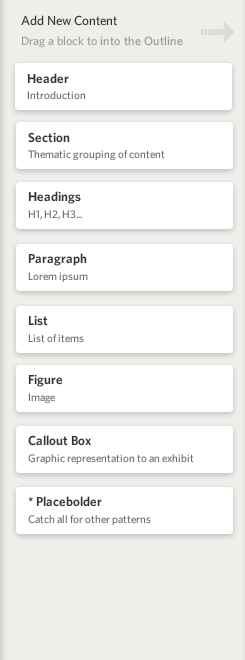
The Pattern Drawer had a set of patterns that a user could drag out into creating a specification card. Once the user dragged out the pattern, they could insert it into their overall card using a simple outline on the right-side; we didn't yet have a way for the user to simply drop it into the content — that came later in Habitat:
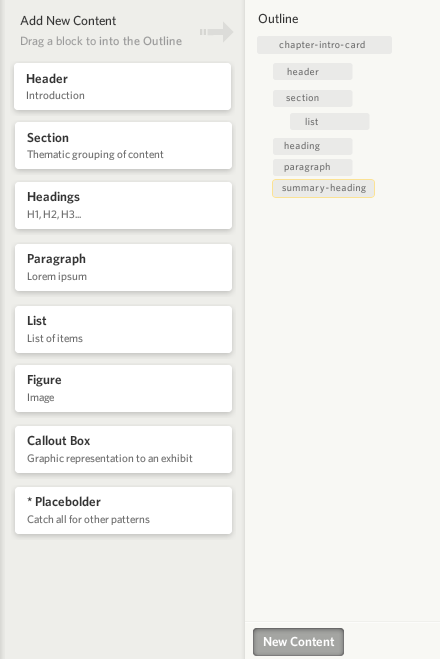
After dropping a pattern into the content, a configuration dialog would come up that allowed the user to add some nuance onto the pattern that was just added:

In the example above, a user is adding a Heading pattern into the content. They could choose a specific type of heading (H2, H3, H4, etc.). Other patterns might have more complicated configuration options. For example, Figure patterns, which can show up in many different ways, could have a title, a caption, an enumeration and designation, etc.
Once the user hit the Set button after dragging the pattern and configuring it, HTML was generated for that given pattern, which could then be given to vendors to do core conversion using the specification as a template. The example above would have produced the following HTML (I'll explain the pattern attribute later):
<h2 pattern="summary-heading" class="blue-summary-heading">Heading 2</h2>Here's what the full UI looked like:
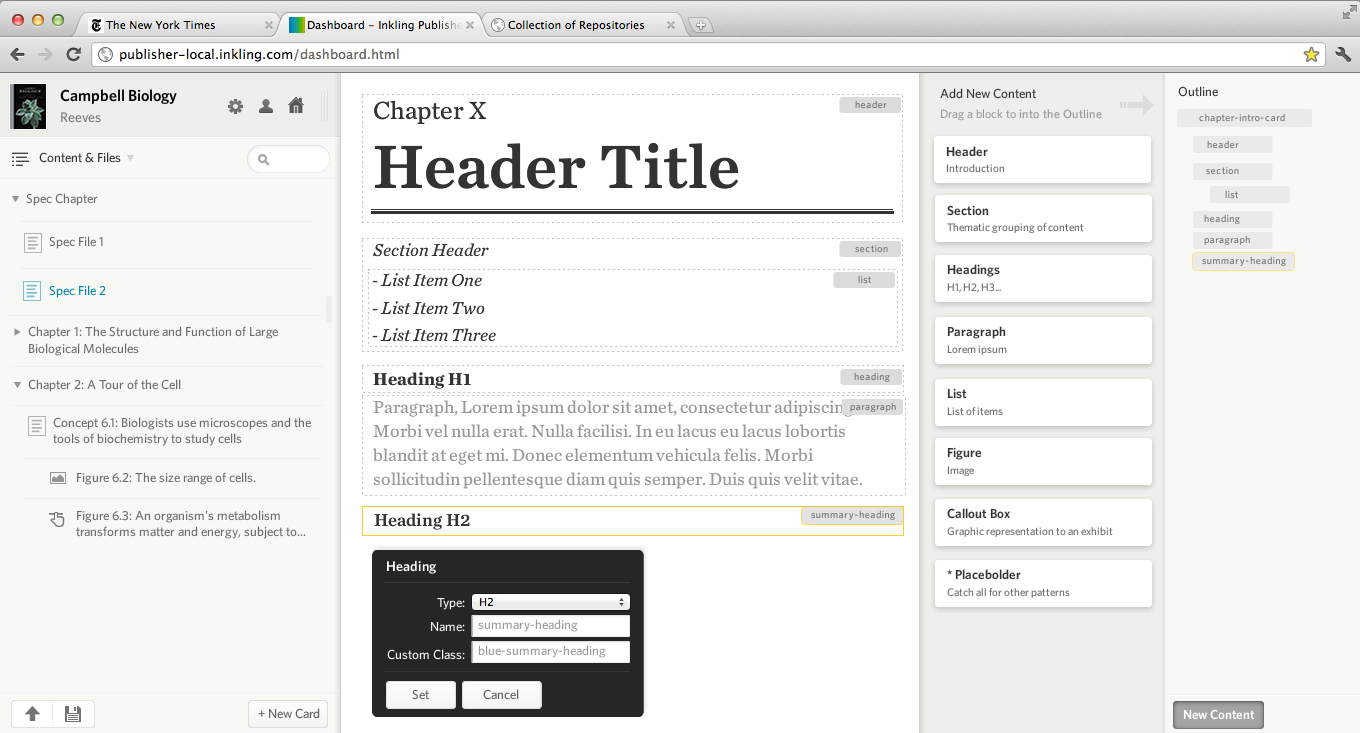
Now, here's the ambitious and crazy part: the templates that were produced by this process were magic. They had extra information behind them with machine readable code that provided the ability to validate an entire eBook against the specification cards.
Now, here's the ambitious and crazy part: the templates that were produced by this process were magic. They had extra information behind them with machine readable code that provided the ability to validate an entire eBook against the specification cards. Then, vendors could take these example specification cards, and use them to fill out an entire eBook as they converted the print book. When they were finished, you could run the resulting vendor generated HTML against the specification cards, seeing if and how they diverged from what the Content Architect said should happen. Basically, you got the ability to audit the core conversion process in a very fast and focused way.
Let's delve a bit into the technical magic behind all of this.
Let's go from the outside in on what was happening technically here.
When a Content Architect dragged patterns out and configured them, they gave them a unique name; notice the Name field below, with summary-heading in it:
Configuring patterns produced example HTML, with an important attribute: the pattern attribute, which points to some special information about the pattern behind this HTML:
<h2 pattern="summary-heading" class="blue-summary-heading">Heading 2</h2>
You can think of the pattern attribute like a little virus that infects the specification card, riding along with all the HTML as a book is fully core converted.
Later on, when the vendor took this HTML as an example of how to deal with something and filled it out with actual content, the HTML snippet would still have the pattern attribute along for the ride on all the filled out book content. The pattern attribute was what hooked back to a magical system that allowed for our book validation. You can think of the pattern attribute like a little virus that infected the specification card, riding along with all the HTML as a book was fully core converted.

So what did that hook link back to in order to do our magic validation?
Well, how do you validate markup? There are many standards for validating markup, from DTDs, to XML Schema, RelaxNG, and Schematron. At the end of the day all of these systems basically provide a way to describe how some markup should be constructed and what is allowed. Then, you can run a validator using those rules on some markup to make sure the rules were followed.
Inkling uses a standard called RelaxNG for these kinds of things. In fact, Inkling has a RelaxNG schema such that whenever you check in a file through Habitat's version control system, which is backed by Subversion, we run what's called a pre-commit hook and validate that the markup is solid, semantically-oriented HTML5. This means checking to make sure there are no inline style attributes; that the markup doesn't have presentationally-oriented markup like the font tag; etc.
RelaxNG is in many ways a pragmatic spec and fairly straightforward. RelaxNG can be written as pure XML, or it has its own short-hand dialect named RelaxNG Compact Syntax that is more readable then the XML version. Here's some example RelaxNG in the Compact Syntax:
heading.level.h2 = element h2 {
id.attr,
heading.classes,
heading.enumerated,
inline.elements
}The fragment above is basically describing an HTML H2 element (element h2), with an ID attribute (id.attr); optional CSS classes (heading.classes); whether its enumerated (heading.enumerated); and optional children inline elements (inline.elements). Some of those refer to other RelaxNG variables that provide further expansion; i.e. inline.elements would be defined somewhere else with other elements that could be added inline.
So here's our answer: the pattern attribute mentioned earlier linked to a small fragment of RelaxNG describing how it should be validated. In the HTML example shown earlier, there was a small RelaxNG schema named summary-heading. This little schema could then be used to validate that any summary headings across a book were being used correctly; in the simple example above this would mainly be that they always provide the custom CSS class blue-summary-heading:
This is a simple example; other patterns such as the Figure pattern could be configured in other much more complicated ways, making it possible to validate and assert that all Figures across a book had mandatory designations and enumerations, captions, etc.
How did these little RelaxNG chunks behind the configured patterns get created?
It turns out that what Content Architects are actually doing when they are configuring patterns is taking a highly generic pattern, such as a Header, and configuring it to be much more specific, such as a Summary Heading; they are whittling away options of what is possible. They are essentially making statements about what is allowed while they are configuring, and then giving those statements a name that can be used in the pattern attribute.
It turns out that the configuration dialog I showed earlier was also doing something magical. Not only was it producing a chunk of HTML for vendors to use for the specification card, but it was also taking a general RelaxNG schema and customizing it to be more specialized and restrictive. Think of it like taking one of those old Pinewood Derby blocks (the general RelaxNG schema) and whittling it down into a specific Pinewood Derby car (the specialized RelaxNG schema produced from the configuration dialog). Pretty crazy.

So, it made the generic, specific, and out popped a little RelaxNG chunk describing the customized pattern, with the given pattern name the user chose, such as Main Figure or Summary Heading. It turned out the Content Architect was actually secretly programming when they were defining a specification: the specification itself became a radically smart template, backed by the RelaxNG schemas for each configured pattern.
Let's go one step deeper into the system now: how did we represent these generic pattern schemas, and then how were they specialized in order to produce a specific schema?
The generic pattern schemas, such as for a Figure pattern in the pattern library, was held in RelaxNG. This RelaxNG was annotated with extra information that provided what could be customized about that pattern, such as whether it needed a designation and enumeration, whether it had a caption, etc. These annotations were read off on the client side to draw the configuration dialog you saw earlier.
RelaxNG allows you to add arbitrary annotations to its rules, using little brackets around the extra arbitrary annotations. Here's an example of what these might look like for the Heading pattern:
[ config:title = "Heading Level"
config:field = "true"
config:fieldType = "list"
config:description = "The level of this heading from H2 through H6"
config:default = "heading.level.h2" ]
heading.level =
(heading.level.h2 |
heading.level.h3 |
heading.level.h4 |
heading.level.h5 |
heading.level.h6)The fragment above has the extra annotations between the [ and ] brackets. The annotations above are basically allowing the user to choose a Heading Level from a list of available options (h2 through h6).
When the configuration dialog needed to draw options for a given pattern, it simply looked at the annotations in the schema and used them to draw itself. Then, as the user was configuring, it was smart enough such that as the user changed the options it used them to stamp out and customize the specific RelaxNG values; the user was literally 'pruning' out options as they were customizing through the UI. Once we had the stamped out, specialized pattern schema, we used a clever algorithm that just walked the RelaxNG grammar to produce example HTML that was written with exactly these specialized rules. The specialized RelaxNG rules were then saved to the server, and were then available for validating an entire eBook once it had been converted, using that magic pattern attribute mentioned earlier to link everything together.
How did everything turn out with this system?
First, it turned out that enabling Content Architects to create specification cards using patterns and configure them without having to know HTML gave a huge boost in productivity, both in-house and in allowing vendors themselves to do Content Architecture.
Second, just having an HTML description of the specification cards instead of PDF, with all the extra features that Habitat brought in, like version control, collaboration, and actionable notes, turned out to provide a strong productivity boost, and having the example HTML really allowed vendors to directly use the sample HTML and load it into their own in-house tools to quickly core convert a book.
Finally, how about the radically smart templates, with all the rules behind them? It turned out that we got a huge productivity and quality boost without even having to turn them on. We never really needed all that intelligence, and it never really turned out to be something that panned out. The extra complexity they brought along was not worth the productivity payoff.
What did we learn from this? For one, we learned how to think about patterns in a much deeper way. Before engaging on this we just thought of patterns as a document that described how you put a book together, but the process of thinking about patterns as incredibly smart forced us to engage with them in a much deep way. This had a hugely positive payoff in terms of future work in Habitat.
...if you find yourself solving hard computer science problems, take a step back and ask yourself "am I solving these hard problems because I might be starting with the wrong problem?"
We also learned some good lessons. One is that if you find yourself solving hard computer science problems, take a step back and ask yourself "am I solving these hard problems because I might be starting with the wrong problem?" It turns out in hindsight that the real problem was the ease of authoring specification cards, or HTML in general, not the quality or validation problem. But we didn't know this going in — when you find yourself solving hard computer science, jump back to a product perspective and make sure you are on the right trajectory.
This is why iterative development is so important. We thought that the authoring and validation pieces had to be deployed together, which turned out to be incorrect. If we had deployed a drastically simpler version of authoring without the smarts, perhaps just using JSON to describe the patterns, we would have discovered the productivity boost that provided. This would have allowed us to ask ourselves whether the validation piece was worth the time.

Even with all of these lessons I still think that what we were doing was compelling and interesting, and is a unique footnote in some of the work the Habitat team has done to fundamentally rethink how eBooks are created. We've tried many different approaches over the last several years. I'm a big believer that if some schemes don't fail, it means you aren't trying radical enough things. Some projects should knock out of the park and be huge successes; others can do ok; and others should crash. Startups in particular should be solving hard problems and trying radical approaches.
With all that said, this system really did enable us to get to the next level in terms of content scale because it decoupled the content speccing process from having to know HTML and having to pass around PDFs, so in that sense it won.
It also led us eventually to a different approach that we call Radically Stupid Templates, and which I'll talk about in a future post. In the long term we actually went the opposite direction for patterns and templates inside of Habitat in terms of their individual smarts; we still have pattern-based authoring but a different spin on it based on what we learned from Radically Smart Templates.
Subscribe to my RSS feed and follow me on Twitter to stay up to date on new posts.
Please note that this is my personal blog — the views expressed on these pages are mine alone and not those of my employer.